

Ok, plenty done this week. Was doing a lot of refactoring and cleaning up. I have been focusing on making the scan pipeline more robust: making it async so it does not block the API, preventing duplicate scans with an atomic guard, splitting full and partial scan modes. I also implemented virtual threads for the most IO-consuming blocking parts of the scan and used a semaphore to bound concurrency so the system does not get overwhelmed.
Performance Improvement #
I tested with 14.15 GB across 2315 files, most averaging 9 MB each, all on a local file system. Before any optimization the scan looked like this:
2026-03-28T08:23:43.661Z : Indexing: /Users/roman/Downloads
2026-03-28T08:23:46.443Z : Time to index: 2781 ms
2026-03-28T08:23:46.444Z : Start Hashing Files
2026-03-28T08:24:48.367Z : Time to hash: 61924 ms
2026-03-28T08:24:48.367Z : Generating Thumbnails
2026-03-28T08:35:18.223Z : Time to generate thumbnails: 629855 ms
2026-03-28T08:35:19.047Z : Time to Persist: 823 msThumbnail generation alone took over 10 minutes. I can foresee this being pointed at SMB mounts too, so the network waiting would be even worse. Need to take care of this now.
My approach was to use virtual threads since they are cheap to create and were made to be blocked. I also use a semaphore to limit how many of them are actually accessing IO at the same time. Virtual threads are cheap but the resources are not. Reading 2000 files at once will slow the system down to a crawl.
Memory usage is also a concern. Hashing and preview generation both load file data into memory, so doing too many at once can easily cause OOM. For a self-hosted app I want to keep it pretty lean, well as lean as I can with Java and Spring Boot 🤣
With 20 max threads:
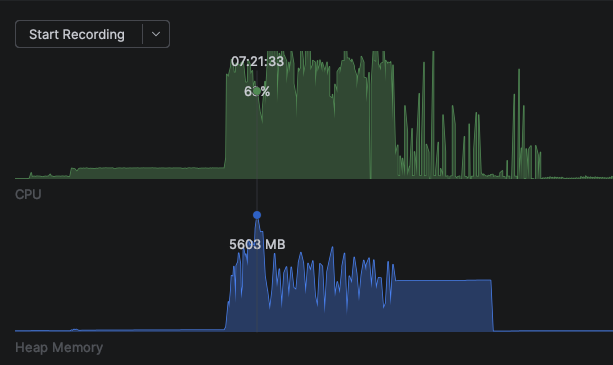
For now each stage runs sequentially, finishing fully before the next starts. Later I could set up a pipeline using channels between threads.
Directory Walking #
The walk phase now only collects file paths and filters for supported image types. EXIF extraction was moved out into it’s own step, so the initial directory scan is much faster.
Hashing & EXIF Extraction #
The EXIF extractor and hasher now run together in the same virtual thread, separate from the walk. I don’t see a point in separating those two for now. They do two separate reads of the same file, but the EXIF read only needs a few bytes of the metadata anyway, which is not bad.
Thumbnail Service #
Because of constant IO waiting, the old sequential approach was very slow:
pathsToScan.forEach(path -> {
Thumbnails.of(path.toFile())
.scale(0.3)
.outputQuality(0.7)
.toFile(outputPath.toFile());
});After switching to virtual threads with a semaphore to bound concurrency:
var semaphore = new Semaphore(20);
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
indexedMedia.forEach(media ->
executor.submit(() -> {
try {
semaphore.acquire();
generatePreview(sourcePath, outputPath);
} finally {
semaphore.release();
}
}));
}Each file gets its own virtual thread, but the semaphore caps how many are doing IO at the same time. The result list uses Collections.synchronizedList since multiple threads are adding to it concurrently.
This brought thumbnail generation from 10.5 minutes down to 1.65 minutes:
Persisting #
For now there is a sequence of steps completing one before the other, but once I turn it into a pipeline, I could have batched persistence where every 100 items or so get added into the DB while others are still being processed. That way we could get live updates to already indexed items without having to wait for all of them to finish.
Summary #
2026-04-03T08:45:17.941+01:00 : Time to walk: 47 ms
2026-04-03T08:45:26.655+01:00 : Time to Extract metadata: 8714 ms
2026-04-03T08:45:26.673+01:00 : Generating Previews
2026-04-03T08:47:05.732+01:00 : Time to generate previews: 99058 ms
2026-04-03T08:47:06.461+01:00 : Time to Persist: 728 ms| Stage | Before | After | Improvement |
|---|---|---|---|
| Initial Walk + Index | 2,781 ms | 47 ms | 98% faster |
| Hashing + EXIF | 61,924 ms | 8,714 ms | 86% faster |
| Previews | 629,855 ms | 99,058 ms | 84% faster |
| Persist | 823 ms | 728 ms | No optimizations were made |
| Total | 695,383 ms (~11.6 min) | 108,547 ms (~1.8 min) | ~84% faster |
The biggest win was in preview generation, which went from over 10 minutes to under 2 by switching to virtual threads with a bounded semaphore. Separating the walk from hashing and EXIF extraction also helped a lot. Overall, a full scan of 2315 files now takes under 2 minutes instead of nearly 12.
Scan Pipeline #
Async Scan with Atomic Boolean Guard #
The scan process (walk, extract metadata, generate previews, persist) can take a while depending on the library size. Two things needed to happen: make it non-blocking and prevent multiple scans from running at the same time.
The scan now runs on a virtual thread so the HTTP request returns immediately. To prevent overlapping scans, an AtomicBoolean acts as a guard. compareAndSet(false, true) atomically checks if a scan is already running and claims the lock in one operation. If another scan is already in progress, it returns false and the request is rejected.
private final AtomicBoolean isScanning = new AtomicBoolean(false);
private boolean startFullScan(String path, boolean isRecursive) {
if (!isScanning.compareAndSet(false, true)) {
return false; // scan already in progress
}
Thread.ofVirtual().start(() -> {
try {
// walk, extract, generate previews, persist...
} finally {
isScanning.set(false);
}
});
return true;
}The finally block guarantees the flag is released even if the scan fails, so a crash does not permanently lock out future scans.
Full Scan vs Partial Scan #
There are now two scan modes. A full scan walks the entire directory tree recursively and diffs against every record in the database. A partial scan only lists the files in a single directory (non-recursive) and diffs against records stored for that specific path.
Both modes follow the same pattern: gather current files, compare against what is already indexed using sets, delete stale entries, generate previews for new ones, and persist. The difference is scope.
// Full scan: walks recursively
List<Path> paths = walkDirectory(path);
// Partial scan: lists a single directory
List<Path> paths = list(path);Partial scans are what the file watcher will trigger. When a change is detected in a directory, only that directory needs to be re-scanned rather than the entire library. This keeps incremental updates fast.
Watch Directory #
The file watcher uses Java’s WatchService and starts via a Spring @EventListener(ApplicationReadyEvent.class) so it kicks in as soon as the app is ready. On startup it walks the scan path recursively and registers every subdirectory for ENTRY_CREATE, ENTRY_DELETE, and ENTRY_MODIFY events.
When a change is detected, the watcher figures out which parent directory was affected, filters for image files, and triggers a partial scan for just that directory. This way only the changed directory is re-indexed instead of the entire library.
To determine what is new or stale, the scan uses set operations on IndexedMedia. The equals and hashCode are configured to ignore fields like lastIndexedTime, lastModifiedTime, and previewPath. This means two records are considered the same based on their hash, path, name, extension, and capture time. The scan loads existing records into a set, compares against the freshly scanned set, and the difference gives stale entries to delete and new entries to persist.
There is currently a bug: directories are only registered for watching at startup. Any new directories created after that are not picked up by the watcher. For now this is fine since a full rescan will pick them up, but it would be nice to handle this automatically.
Skipping Already Indexed Files #
A full rescan still walks the directory and extracts metadata for every file, but after that it diffs against the database. Only files that are not already indexed get their previews generated and persisted. Files that were deleted from the file system but still exist in the database get cleaned up as well. Since preview generation is the most expensive step by far, skipping already indexed files saves a lot of time on repeated scans.
File Handling #
Removing Unsupported Formats #
Thumbnailator does not support HEIC/HEIF files. Rather than failing silently during preview generation, the supported formats are now defined explicitly in ImageTools and unsupported files are filtered out during the walk phase.
private static final Set<String> IMAGE_EXTENSIONS = Set.of(
"jpg", "jpeg", "png", "webp", "gif", "bmp", "wbmp"
);
public static Boolean isImage(Path path) {
FileNameParts fileNameParts = getFileParts(path);
return IMAGE_EXTENSIONS
.contains(fileNameParts.extension().toLowerCase());
}This means HEIC files are excluded from indexing entirely for now.
Preventing Deeply Nested Preview Folders #
The original approach mirrored the source directory structure for previews, which meant deeply nested folders that were hard to clean up. Now previews use a hash-based folder structure. The first two characters of the hash become the first directory, the next two become the second, and the rest of the hash is the filename:
public String generatePreviewPathFromHash() {
return hash.substring(0, 2) + "/" + hash.substring(2, 4) + "/" + hash.substring(8) + getPossibleExtension();
}This keeps the directory tree shallow and evenly distributed regardless of where the source files live.
What’s next #
- Authentication and looking into an admin panel with roles
- Docker build for easier deployment
- Smaller fixes and cleanup