
In most systems, reads and writes don’t scale the same way, and they rarely need the same data shape. As domains grow more complex, forcing a single model to handle both creates bloated entities and scaling bottlenecks. This article covers two patterns that address this directly: CQRS, which separates the write and read paths, and Event Sourcing, which replaces mutable state with an append-only log of what happened.
CQRS #
Command Query Responsibility Segregation
Separate the write model (commands) from the read model (queries). Instead of one service/entity/repository doing both reads and writes, you split them into two distinct paths.
| Problem with shared model | CQRS solution |
|---|---|
| Read and write traffic scale differently | Can optimize or scale each side independently |
| Business logic bleeds into read paths | Write path owns rules; read path is pure data retrieval |
| Entities become bloated trying to serve both needs | Focused, single-purpose classes on each side |
Command (Writes) #
- Receives a command object, a simple DTO/record describing the intent
- Passes through validation and business rules
- Mutates state and persists changes
Query (Reads) #
- Returns DTOs shaped for the consumer, no domain objects leak out
- No business logic, no side effects
- Free to use optimized queries, projections, caching
Levels of Separation #
Level 1 - Logical (same DB) #
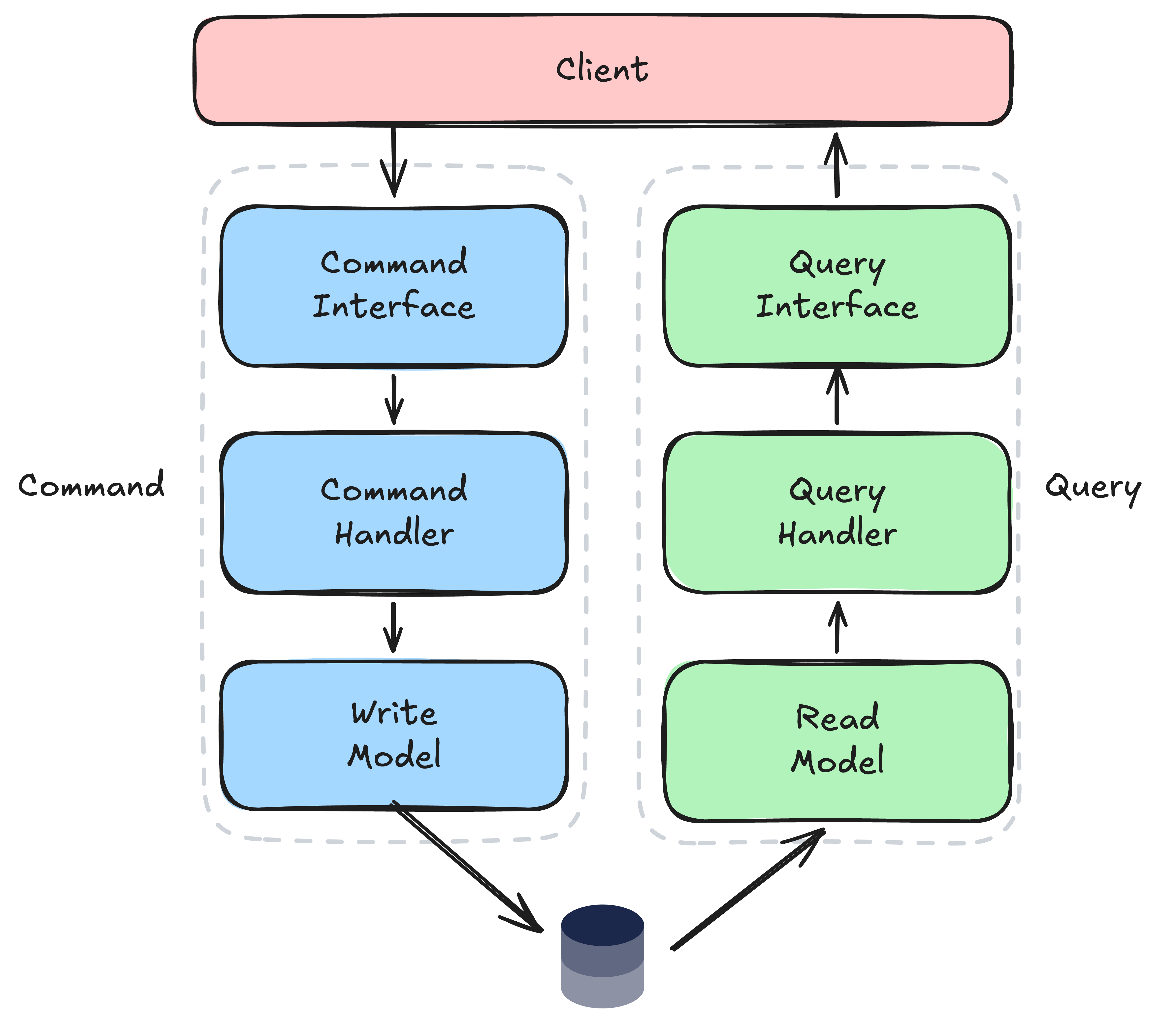
- Separate command/query services and DTOs
- Same database, same tables
- Minimal cost, just code organization
- This is where most teams should start and often stay
Level 2 - Separate data stores #
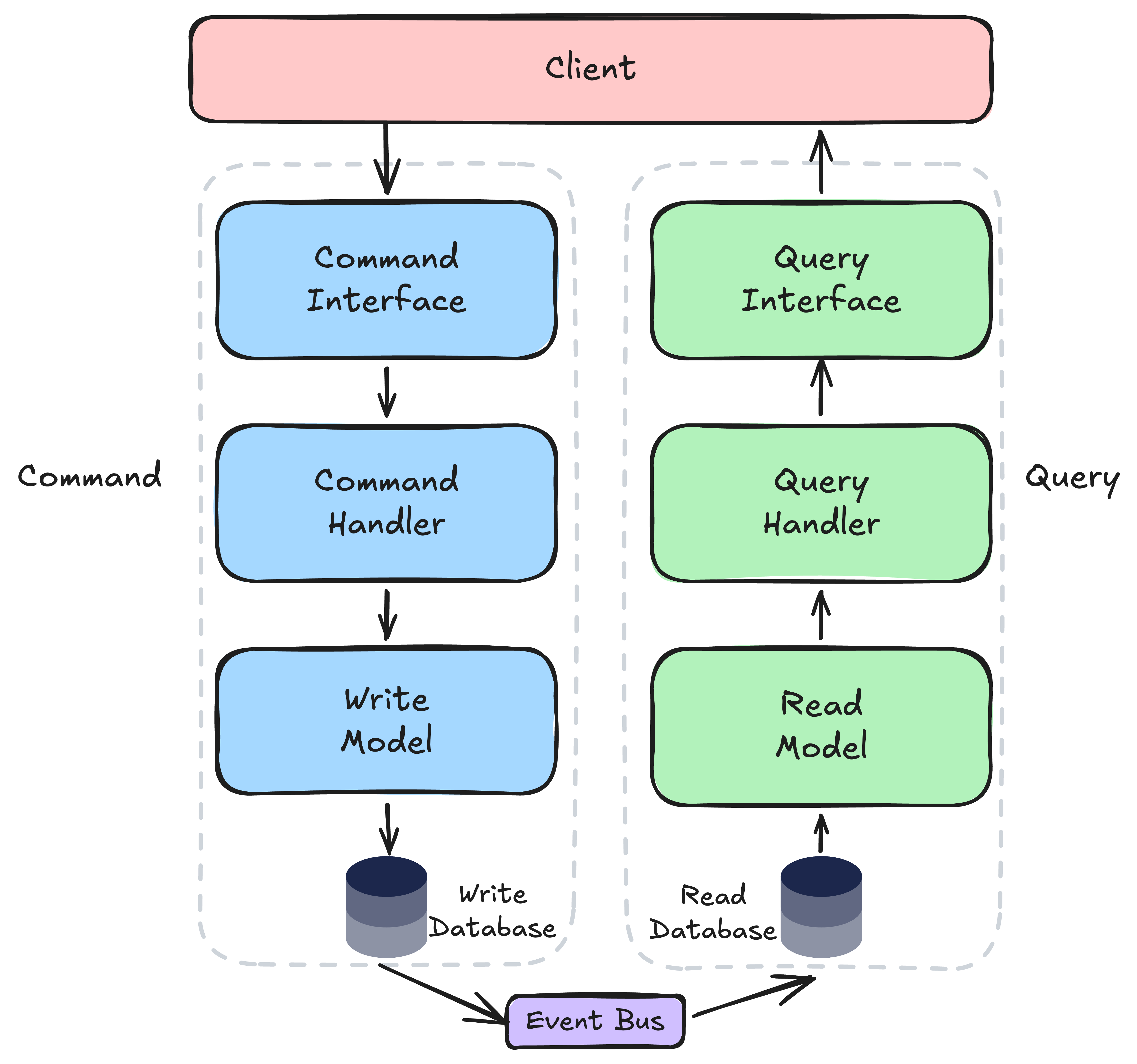
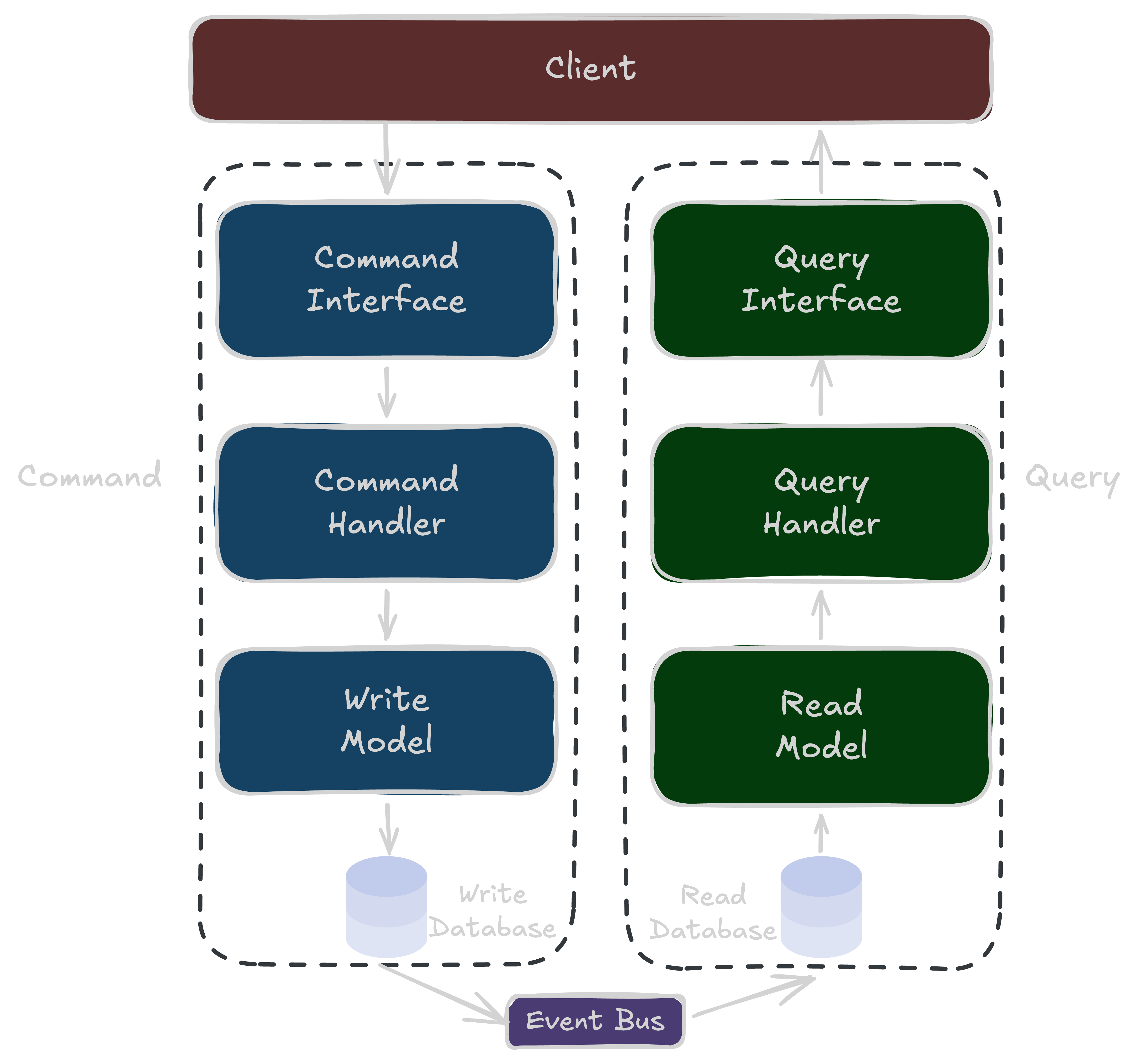
- Write side - persists to the source-of-truth store (relational DB for ACID guarantees); publishes change events
- Read side - consumes events projected into a read store chosen to fit the query pattern (Elasticsearch for search optimized)
- Eventual consistency - reads may lag behind writes
- Significant operational complexity
Level 3 - Event Sourcing + CQRS #
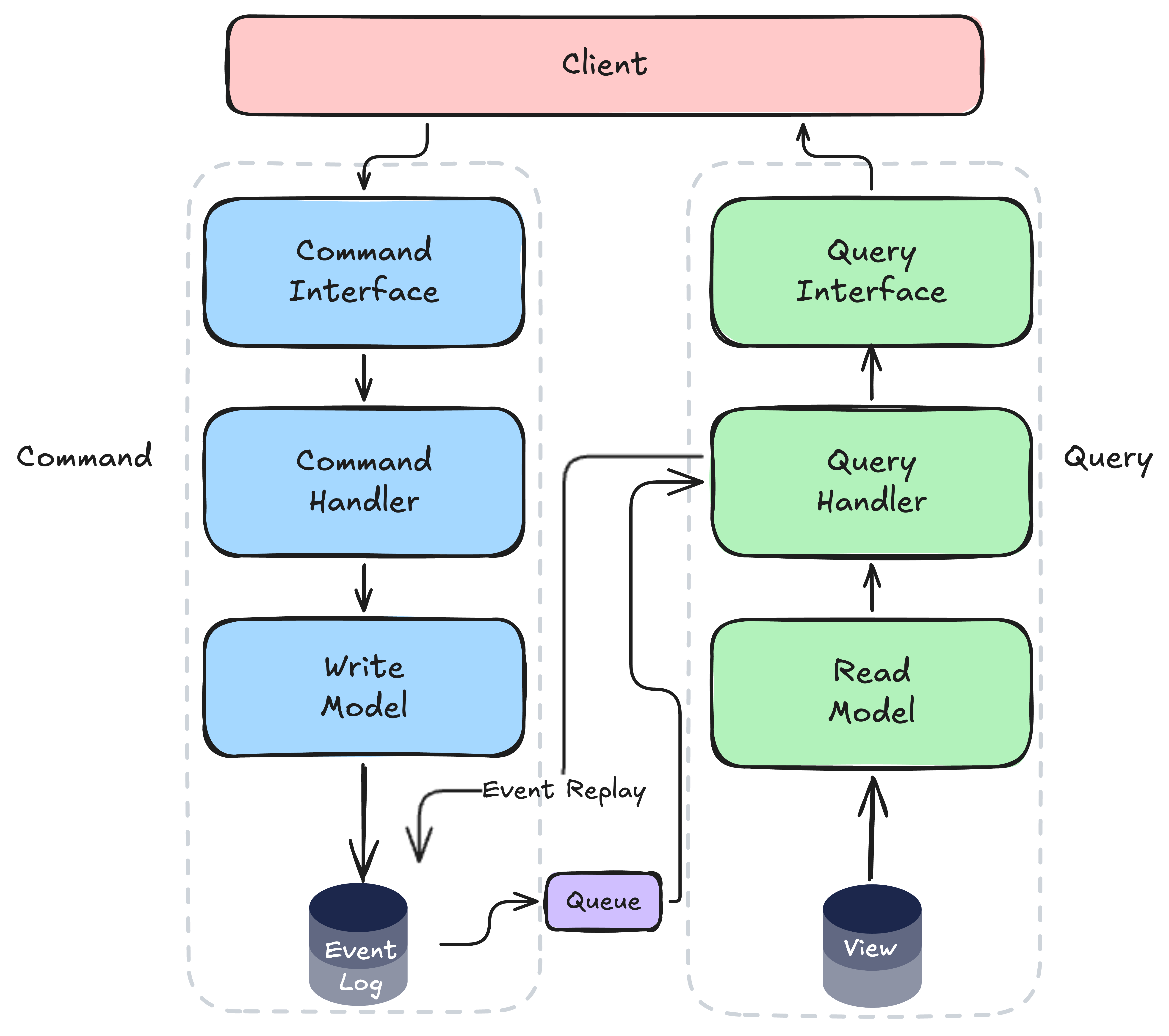
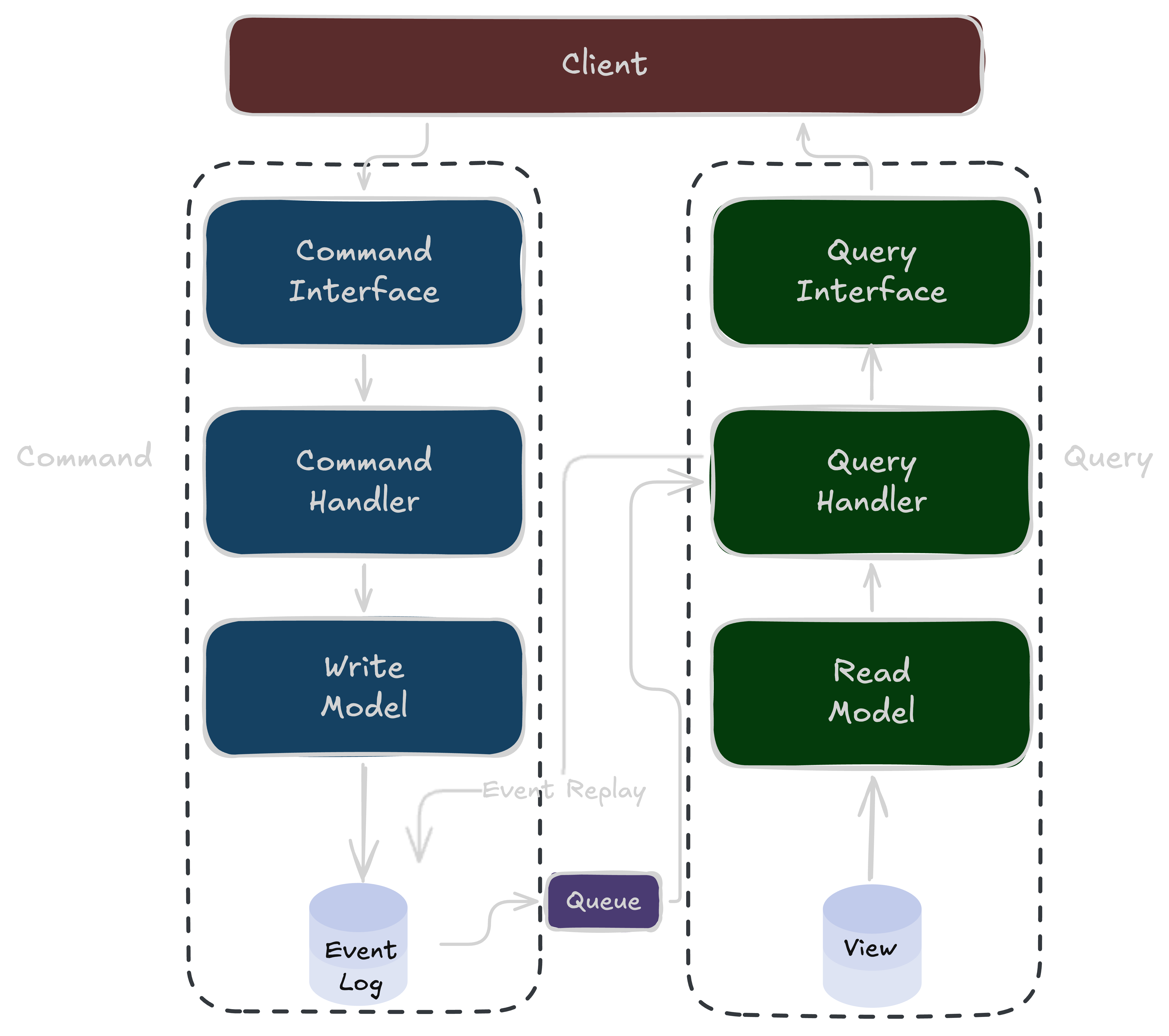
- Write side - appends immutable events to an event store (no mutable state, no UPDATE/DELETE)
- Read side - consumes the event stream and builds purpose-built projections (read models)
- Hydration replaces direct DB reads on the write side, aggregate state is rebuilt from its events before each command
- Full audit log
When to Use #
- Read and write models diverge significantly
- Different consumers need different views of the same data
- Complex domain logic on the write side
- Read/write traffic has very different scaling needs
- Simple CRUD with straightforward entities
- Read and write shapes are nearly identical
Event Sourcing #
- Store every state change as an immutable event instead of just the current state
- Events are appended to an event log (event store) in order, never updated or deleted
- Current state is derived by replaying events from the beginning (or from a snapshot)
- Event Store: append-only log of all events, acts as the source of truth
- Projection/view: a read model built by processing events (e.g. current account balance)
- Snapshot: periodic checkpoint of state to avoid replaying the entire log on every read
- Hydration (Rehydration): load one aggregate’s events and apply them in memory to reconstruct current state
- Write-side (typical): reconstruct aggregate state before handling a command; happens on every incoming command
- Replay: process events across many aggregates to build or rebuild a projection from scratch
- Read-side (typical): rebuild or create projections on schema changes or for new consumers
- Full audit trail - every change is recorded with who did what and when
- Time travel - reconstruct state at any point in the past
- Decoupling - consumers can build their own read models from the same event stream
- Works naturally with event-driven architectures
- Querying current state is indirect - requires projections or snapshots
- Event schema evolution is hard - old events must stay readable as the schema changes
- Storage grows indefinitely - events are never deleted
- Increased complexity vs. simple CRUD
Event sourcing is commonly used with CQRS: the write side appends events, the read side builds optimized projections. This separates the complexity of event replay from the simplicity of read queries.
- Banking / Finance: immutable transaction ledger
- Audit-heavy systems: compliance, healthcare records